문서를 불러오는 중...
MySQL 9.5 Reference Manual 9.5의 19.4.5 Using Replication for Scale-Out의 한국어 번역본입니다.
아래의 경우에 피드백에서 신고해주신다면 반영하겠습니다.
감사합니다 :)
Replication을 스케일 아웃 솔루션으로 사용할 수 있습니다. 즉, 합리적인 한계 내에서 데이터베이스 쿼리의 부하를 여러 데이터베이스 서버에 분산하고자 할 때 사용할 수 있습니다.
Replication은 하나의 소스에서 하나 이상의 레플리카로 분산되는 방식으로 동작하기 때문에, 스케일 아웃을 위해 replication을 사용하는 것은 읽기 작업이 많고 쓰기/업데이트가 적은 환경에서 가장 효과적입니다. 대부분의 웹사이트가 이 범주에 속합니다. 사용자는 웹사이트를 탐색하며 아티클, 포스트를 읽거나 제품을 조회합니다. 업데이트는 세션 관리 중이거나, 구매를 하거나 포럼에 코멘트/메시지를 추가할 때만 발생합니다.
이러한 상황에서 replication은 읽기를 레플리카에 분산시키는 동시에, 쓰기가 필요할 때 웹 서버가 소스와 통신할 수 있게 해 줍니다. 이 시나리오에 대한 예시 replication 레이아웃은
Figure 19.1, “Using Replication to Improve Performance During Scale-Out”에서 확인할 수 있습니다.
Figure 19.1 Using Replication to Improve Performance During Scale-Out
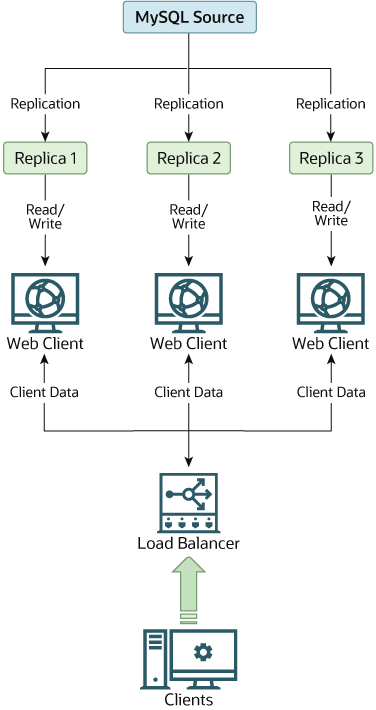
데이터베이스 액세스를 담당하는 코드 부분이 제대로 추상화/모듈화되어 있다면, 이를 replication이 구성된 환경에서 동작하도록 변환하는 작업은 매우 원활하고 수월할 것입니다. 데이터베이스 액세스 구현을 변경하여, 모든 쓰기는 소스로 보내고, 읽기는 소스 또는 레플리카로 보내도록 하십시오. 코드가 이 수준의 추상화를 갖추지 못했다면, replication 시스템을 구축하는 것이 코드를 정리할 수 있는 기회이자 동기가 됩니다. 다음 기능들을 구현하는 래퍼 라이브러리 또는 모듈을 만드는 것으로 시작하십시오:
safe_writer_connect()
safe_reader_connect()
safe_reader_statement()
safe_writer_statement()
각 함수 이름에 있는 safe_는 함수가 모든 오류 조건 처리를 담당한다는 의미입니다. 함수 이름은 다르게 사용해도 됩니다. 중요한 점은 읽기용 커넥션, 쓰기용 커넥션, 읽기 수행, 쓰기 수행에 대해 통일된 인터페이스를 갖는 것입니다.
그런 다음 클라이언트 코드를 래퍼 라이브러리를 사용하도록 변환하십시오. 처음에는 고통스럽고 두려운 과정일 수 있지만, 장기적으로는 그만한 가치가 있습니다. 방금 설명한 접근 방식을 사용하는 모든 애플리케이션은 여러 레플리카가 포함된 경우를 포함해 소스/레플리카 구성을 활용할 수 있습니다. 코드는 유지 관리가 훨씬 쉬워지고, 트러블슈팅 옵션을 추가하는 일도 사소해집니다. 단지 하나 또는 두 개의 함수만 수정하면 됩니다(예를 들어 각 문이 걸린 시간이나, 실행된 문 중 어느 것이 오류를 발생시켰는지를 로그로 남기기 위해서).
코드를 많이 작성해 둔 상태라면, 변환 스크립트를 작성해서 변환 작업을 자동화하고 싶을 수 있습니다. 이상적으로는 코드가 일관된 프로그래밍 스타일 컨벤션을 사용하고 있어야 합니다. 그렇지 않다면, 어차피 코드를 다시 작성하는 편이 더 나을 가능성이 크며, 최소한 일관된 스타일을 사용하도록 코드를 수작업으로 정리하는 편이 좋습니다.
19.4.4 Using Replication with Different Source and Replica Storage Engines
19.4.6 Replicating Different Databases to Different Replicas