문서를 불러오는 중...
MySQL 9.5 Reference Manual 9.5의 25.2 NDB Cluster Overview의 한국어 번역본입니다.
아래의 경우에 피드백에서 신고해주신다면 반영하겠습니다.
감사합니다 :)
25.2.1 NDB Cluster Core Concepts
25.2.2 NDB Cluster Nodes, Node Groups, Fragment Replicas, and Partitions
25.2.3 NDB Cluster Hardware, Software, and Networking Requirements
25.2.4 What is New in MySQL NDB Cluster 9.5
25.2.5 Options, Variables, and Parameters Added, Deprecated or Removed in NDB 9.5
25.2.6 MySQL Server Using InnoDB Compared with NDB Cluster
25.2.7 Known Limitations of NDB Cluster
NDB Cluster는 공유-없음(shared-nothing) 시스템에서 인메모리 데이터베이스의 클러스터링을 가능하게 하는 기술입니다. 공유-없음 아키텍처는 시스템이 매우 저렴한 하드웨어로 동작할 수 있게 해 주며, 하드웨어나 소프트웨어에 대해 요구되는 특정 조건을 최소화합니다.
NDB Cluster는 단일 장애 지점(single point of failure)이 존재하지 않도록 설계되었습니다. 공유-없음 시스템에서 각 구성 요소는 자체 메모리와 디스크를 가지는 것이 기대되며, 네트워크 공유, 네트워크 파일 시스템, SAN과 같은 공유 스토리지 메커니즘의 사용은 권장되지도, 지원되지도 않습니다.
NDB Cluster는 표준 MySQL 서버와 NDB라는 인메모리 클러스터형 스토리지 엔진을 통합합니다(“_N_etwork _D_ata _B_ase”의 약자). 이 문서에서 NDB라는 용어는 스토리지 엔진에 특화된 설정 부분을 가리키는 반면, “MySQL NDB Cluster”는 하나 이상의 MySQL 서버와 NDB 스토리지 엔진의 조합을 의미합니다.
NDB Cluster는 호스트로 알려진 컴퓨터 집합으로 구성되며, 각 호스트는 하나 이상의 프로세스를 실행합니다. 이러한 프로세스는 노드라 불리며, NDB 데이터에 대한 액세스를 제공하는 MySQL 서버, 데이터를 저장하는 데이터 노드, 하나 이상의 관리 서버, 그리고 경우에 따라 다른 특수한 데이터 액세스 프로그램을 포함할 수 있습니다. NDB Cluster에서 이러한 구성 요소들의 관계는 다음과 같습니다:
Figure 25.1 NDB Cluster Components
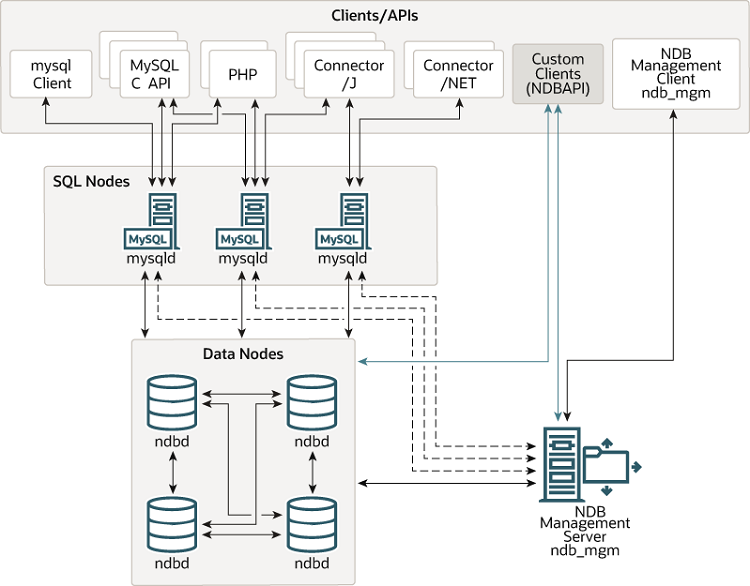
이 모든 프로그램은 함께 동작하여 NDB Cluster를 형성합니다(참고:
Section 25.5, “NDB Cluster Programs”). NDB 스토리지 엔진에 의해 데이터가 저장되면, 테이블(및 테이블 데이터)은 데이터 노드에 저장됩니다.
이러한 테이블은 클러스터 내의 다른 모든 MySQL 서버(SQL 노드)에서 직접 접근할 수 있습니다. 따라서 클러스터에 데이터를 저장하는 급여 애플리케이션에서 하나의 애플리케이션이 어떤 직원의 급여를 갱신하면, 이 데이터를 조회하는 다른 모든 MySQL 서버는 이 변경 사항을 즉시 확인할 수 있습니다.
NDB Cluster 9.5 SQL 노드는 MySQL Server 데몬인 mysqld를 사용하며, 이는 MySQL Server 9.5 배포본에 포함된 mysqld와 동일합니다. 어떤 버전이든 NDB Cluster에 연결되지 않은 mysqld 인스턴스는 NDB 스토리지 엔진을 사용할 수 없으며 어떠한 NDB Cluster 데이터에도 접근할 수 없다는 점을 반드시 유념해야 합니다.
NDB Cluster의 데이터 노드에 저장된 데이터는 미러링될 수 있습니다. 클러스터는 개별 데이터 노드의 장애를, 트랜잭션 상태 손실로 인해 일부 트랜잭션이 중단(abort)되는 것 이외에는 다른 영향 없이 처리할 수 있습니다. 트랜잭션 기반 애플리케이션은 트랜잭션 실패를 처리하도록 설계되는 것이 기대되므로, 이는 문제의 원인이 되어서는 안 됩니다.
개별 노드는 중지한 후 다시 시작할 수 있으며, 그 후 시스템(클러스터)에 재참여할 수 있습니다. 롤링 재시작(모든 노드를 차례대로 재시작하는 방식)은 구성 변경 및 소프트웨어 업그레이드를 수행할 때 사용됩니다(참고: Section 25.6.5, “Performing a Rolling Restart of an NDB Cluster”). 롤링 재시작은 온라인으로 새로운 데이터 노드를 추가하는 과정의 일부로도 사용됩니다(참고 Section 25.6.7, “Adding NDB Cluster Data Nodes Online”). 데이터 노드, 이들이 NDB Cluster에서 어떻게 구성되는지, 그리고 NDB Cluster 데이터를 어떻게 처리하고 저장하는지에 대한 자세한 정보는 Section 25.2.2, “NDB Cluster Nodes, Node Groups, Fragment Replicas, and Partitions”를 참조하십시오.
NDB Cluster 데이터베이스의 백업 및 복원은 NDB Cluster 관리 클라이언트에 존재하는 NDB-네이티브 기능과 NDB Cluster 배포본에 포함된 ndb_restore 프로그램을 사용하여 수행할 수 있습니다. 자세한 내용은
Section 25.6.8, “Online Backup of NDB Cluster” 및
Section 25.5.23, “ndb_restore — Restore an NDB Cluster Backup”를 참조하십시오.
또한 이 목적을 위해 제공되는 표준 MySQL 기능인 mysqldump 및 MySQL 서버를 사용할 수도 있습니다. 더 많은 정보는 Section 6.5.4, “mysqldump — A Database Backup Program”를 참조하십시오.
NDB Cluster 노드는 노드 간 통신을 위해 서로 다른 전송(transport) 메커니즘을 사용할 수 있습니다. 대부분의 실제 배포에서 표준 100 Mbps 이상 이더넷 하드웨어 상의 TCP/IP가 사용됩니다.
25.1 General Information
25.2.1 NDB Cluster Core Concepts