문서를 불러오는 중...
MySQL 9.5 Reference Manual 9.5의 25.2.2 NDB Cluster Nodes, Node Groups, Fragment Replicas, and Partitions의 한국어 번역본입니다.
아래의 경우에 피드백에서 신고해주신다면 반영하겠습니다.
감사합니다 :)
이 절에서는 NDB Cluster가 데이터를 저장하기 위해 데이터를 분할하고 복제하는 방식에 대해 설명합니다.
이 주제를 이해하는 데 핵심이 되는 여러 개념을 다음 몇 개의 단락에서 설명합니다.
Data node.
ndbd 또는 ndbmtd 프로세스로서, 하나 이상의 fragment replica를 저장합니다. 즉, 해당 노드가 속한 node group에 할당된 partition(이 절의 후반부에서 설명)을 복사해 둔 것입니다.
각 data node는 별도의 컴퓨터에 위치하는 것이 좋습니다. 하나의 컴퓨터에서 여러 개의 data node 프로세스를 호스팅하는 것도 가능하지만, 일반적으로는 권장되지 않습니다.
“node”와 “data node”라는 용어는 ndbd 또는 ndbmtd 프로세스를 가리킬 때 상호 교환적으로 사용되는 경우가 많습니다. 이 설명에서 관리 노드(ndb_mgmd 프로세스)와 SQL node(mysqld 프로세스)가 언급될 때는 그렇게 명시해서 구분합니다.
Node group.
Node group은 하나 이상의 node로 구성되며, partition 또는 fragment replica 집합(다음 항목 참조)을 저장합니다.
NDB Cluster에서 node group의 개수는 직접 설정할 수 있는 값이 아닙니다. 이는 data node의 수와 fragment replica 수(NoOfReplicas 설정 파라미터)의 함수이며, 아래와 같이 계산됩니다:
1[# of node groups] = [# of data nodes] / NoOfReplicas
따라서, data node가 4개인 NDB Cluster에서 config.ini 파일에서 NoOfReplicas가 1로 설정되어 있으면 node group은 4개이고, NoOfReplicas가 2로 설정되어 있으면 node group은 2개, 4로 설정되어 있으면 node group은 1개입니다. Fragment replica는 이 절의 후반부에서 설명합니다. NoOfReplicas에 대한 더 자세한 내용은 Section 25.4.3.6, “Defining NDB Cluster Data Nodes”를 참조하십시오.
참고
NDB Cluster 내의 모든 node group은 동일한 개수의 data node를 가져야 합니다.
새로운 node group(따라서 새로운 data node)을 동작 중인 NDB Cluster에 온라인으로 추가할 수 있습니다. 자세한 내용은 Section 25.6.7, “Adding NDB Cluster Data Nodes Online”을 참조하십시오.
Partition.
Partition은 클러스터에 의해 저장되는 데이터의 일부입니다. 각 node는 자신에게 할당된 partition 각각에 대해 적어도 하나의 복사본(즉, 최소 하나의 fragment replica)을 클러스터에 사용할 수 있도록 유지할 책임이 있습니다.
NDB Cluster에서 기본적으로 사용되는 partition 개수는 data node 수와 data node에서 사용 중인 LDM 스레드 수에 따라 다음과 같이 결정됩니다:
1[# of partitions] = [# of data nodes] * [# of LDM threads]
Data node가 ndbmtd를 실행하는 경우, LDM 스레드 수는 MaxNoOfExecutionThreads 설정에 의해 제어됩니다. ndbd를 사용할 때는 단일 LDM 스레드만 존재하며, 이는 클러스터에 참여하는 node 수와 클러스터 partition 수가 같음을 의미합니다. ndbmtd를 사용할 때 MaxNoOfExecutionThreads가 3 이하로 설정되어 있는 경우에도 마찬가지입니다. (이 파라미터 값이 증가함에 따라 LDM 스레드 수가 증가하지만, 증가 양상이 엄밀한 선형 관계는 아니라는 점과, 이 값을 설정할 때 추가적인 제약이 있다는 점에 유의해야 합니다. 자세한 정보는 MaxNoOfExecutionThreads의 설명을 참조하십시오.)
NDB and user-defined partitioning.
NDB Cluster는 일반적으로 NDBCLUSTER 테이블을 자동으로 파티셔닝합니다. 그러나 NDBCLUSTER 테이블에 대해 사용자 정의 파티셔닝을 사용하는 것도 가능합니다. 이 경우 다음 제한 사항이 적용됩니다:
KEY 및 LINEAR KEY 파티셔닝 방식만 NDB 테이블에서 프로덕션 용도로 지원됩니다.
임의의 NDB 테이블에 대해 명시적으로 정의할 수 있는 partition의 최대 개수는
8 * [number of LDM threads] * [number of node groups]이며, NDB Cluster에서 node group의 개수는 이 절에서 앞서 설명한 대로 결정됩니다. Data node 프로세스로 ndbd를 실행하는 경우, LDM 스레드 수를 설정해도 효과가 없습니다(이는 ThreadConfig가 ndbmtd에만 적용되기 때문입니다). 이런 경우, 이 값을 이 계산을 수행하는 목적에 한해 1과 동일한 것으로 취급할 수 있습니다.
Section 25.5.3, “ndbmtd — The NDB Cluster Data Node Daemon (Multi-Threaded)”를 참조하여 자세한 정보를 확인하십시오.
NDB Cluster와 사용자 정의 파티셔닝에 관한 더 자세한 내용은 Section 25.2.7, “Known Limitations of NDB Cluster” 및 Section 26.6.2, “Partitioning Limitations Relating to Storage Engines”를 참조하십시오.
Fragment replica.
Fragment replica는 클러스터 partition의 복사본입니다. Node group 내의 각 node는 하나의 fragment replica를 저장합니다. 이는 partition replica라고 부르기도 합니다. Fragment replica의 개수는 node group당 node 개수와 같습니다.
Fragment replica는 하나의 node에 전체가 속합니다. 하나의 node는 여러 개의 fragment replica를 저장할 수 있으며, 일반적으로 그렇게 합니다.
다음 다이어그램은 ndbd를 실행하는 네 개의 data node가 두 개의 node group(각각 두 개의 node로 구성)으로 구성된 NDB Cluster를 보여 줍니다. Node 1과 2는 node group 0에 속하고, node 3과 4는 node group 1에 속합니다.
참고
여기에는 data node만 표시되어 있습니다. 동작하는 NDB Cluster에는 클러스터 관리를 위한 ndb_mgmd 프로세스와 클러스터에 저장된 데이터에 접근하기 위한 최소 한 개의 SQL node가 필요하지만, 그림의 명확성을 위해 이들은 생략되었습니다.
Figure 25.2 NDB Cluster with Two Node Groups
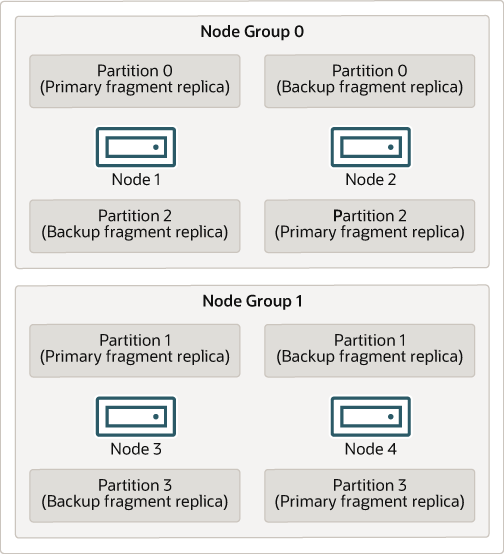
클러스터에 의해 저장되는 데이터는 0, 1, 2, 3의 네 개 partition으로 나뉩니다. 각 partition은 동일한 node group에 여러 복사본으로 저장됩니다. Partition은 다음과 같이 번갈아 가며 node group에 저장됩니다:
Partition 0은 node group 0에 저장됩니다. Primary fragment replica(주 복사본)는 node 1에 저장되고, backup fragment replica(partition의 백업 복사본)는 node 2에 저장됩니다.
Partition 1은 다른 node group(node group 1)에 저장됩니다. 이 partition의 primary fragment replica는 node 3에 있고, backup fragment replica는 node 4에 있습니다.
Partition 2는 node group 0에 저장됩니다. 그러나 두 fragment replica의 배치는 Partition 0과 반대입니다. Partition 2의 경우 primary fragment replica는 node 2에 저장되고, backup은 node 1에 저장됩니다.
Partition 3은 node group 1에 저장되며, 두 fragment replica의 배치는 Partition 1과 반대입니다. 즉, primary fragment replica는 node 4에 있고, backup은 node 3에 있습니다.
이것이 NDB Cluster의 지속적인 동작과 관련해 의미하는 바는 다음과 같습니다. 클러스터에 참여하는 각 node group마다 최소한 하나의 node가 동작 중인 한, 클러스터는 모든 데이터의 완전한 복사본을 가지고 있으며 계속 유효합니다. 이는 다음 다이어그램에서 설명합니다.
Figure 25.3 Nodes Required for a 2x2 NDB Cluster
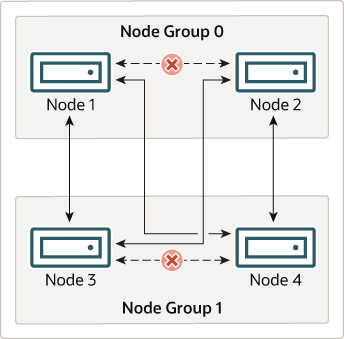
이 예제에서 클러스터는 두 개의 node group으로 구성되며, 각 node group은 두 개의 data node로 이루어져 있습니다. 각 data node는 ndbd 인스턴스를 실행하고 있습니다. Node group 0에서 최소 한 개의 node와 node group 1에서 최소 한 개의 node를 포함하는 임의의 조합이면 클러스터를 “살아 있는” 상태로 유지하는 데 충분합니다. 그러나 하나의 node group에서 두 node가 모두 장애가 나면, 다른 node group에 남아 있는 두 node의 조합만으로는 충분하지 않습니다. 이러한 상황에서는 클러스터가 하나의 전체 partition을 상실하게 되며, 따라서 더 이상 모든 NDB Cluster 데이터에 대한 완전한 접근을 제공할 수 없습니다.
단일 NDB Cluster 인스턴스에서 지원되는 최대 node group 수는 48개입니다.
25.2.1 NDB Cluster Core Concepts
25.2.3 NDB Cluster Hardware, Software, and Networking Requirements