문서를 불러오는 중...
MySQL 9.5 Reference Manual 9.5의 25.7 NDB Cluster Replication의 한국어 번역본입니다.
아래의 경우에 피드백에서 신고해주신다면 반영하겠습니다.
감사합니다 :)
25.7.1 NDB Cluster Replication: Abbreviations and Symbols
25.7.2 General Requirements for NDB Cluster Replication
25.7.3 Known Issues in NDB Cluster Replication
25.7.4 NDB Cluster Replication Schema and Tables
25.7.5 Preparing the NDB Cluster for Replication
25.7.6 Starting NDB Cluster Replication (Single Replication Channel)
25.7.7 Using Two Replication Channels for NDB Cluster Replication
25.7.8 Implementing Failover with NDB Cluster Replication
25.7.9 NDB Cluster Backups With NDB Cluster Replication
25.7.10 NDB Cluster Replication: Bidirectional and Circular Replication
25.7.11 NDB Cluster Replication Using the Multithreaded Applier
25.7.12 NDB Cluster Replication Conflict Resolution
NDB Cluster는 비동기식 복제를 지원하며, 일반적으로 간단히 “복제”라고 부릅니다. 이 절에서는 하나의 NDB Cluster로 동작하는 컴퓨터 그룹이 두 번째 컴퓨터 또는 컴퓨터 그룹으로 복제하는 구성을 설정하고 관리하는 방법을 설명합니다.
여기서는 독자가 이 Manual의 다른 곳에서 설명된 표준 MySQL 복제에 어느 정도 익숙하다고 가정합니다. (자세한 내용은 Chapter 19, Replication을 참조하십시오).
참고
NDB Cluster는 GTID를 사용하는 복제를 지원하지 않습니다. 반동기식 복제 및 그룹 복제도 NDB 스토리지 엔진에서는 지원되지 않습니다.
일반적인 (클러스터가 아닌) 복제에는 소스 서버와 레플리카 서버가 포함되며, 복제할 작업과 데이터가 소스에서 시작되기 때문에 소스라는 이름이 붙고, 이를 수신하는 쪽이 레플리카입니다. NDB Cluster에서 복제는 개념적으로 매우 비슷하지만, 두 개의 전체 클러스터 간의 복제를 포함한 여러 가지 다른 구성을 다룰 수 있으므로 실제로는 더 복잡할 수 있습니다.
NDB Cluster 자체는 클러스터링 기능을 위해 NDB 스토리지 엔진에 의존하지만, 복제된 테이블의 레플리카 측 복사본에 대해 스토리지 엔진으로서 NDB를 사용할 필요는 없습니다 (Replication from NDB to other storage engines를 참조하십시오).
그러나 가용성을 최대화하기 위해서는 하나의 NDB Cluster에서 다른 NDB Cluster로 복제하는 것이 가능하며(또한 더 바람직합니다). 아래 그림에 나타난 대로, 이 시나리오를 설명합니다.
Figure 25.10 NDB Cluster-to-Cluster Replication Layout
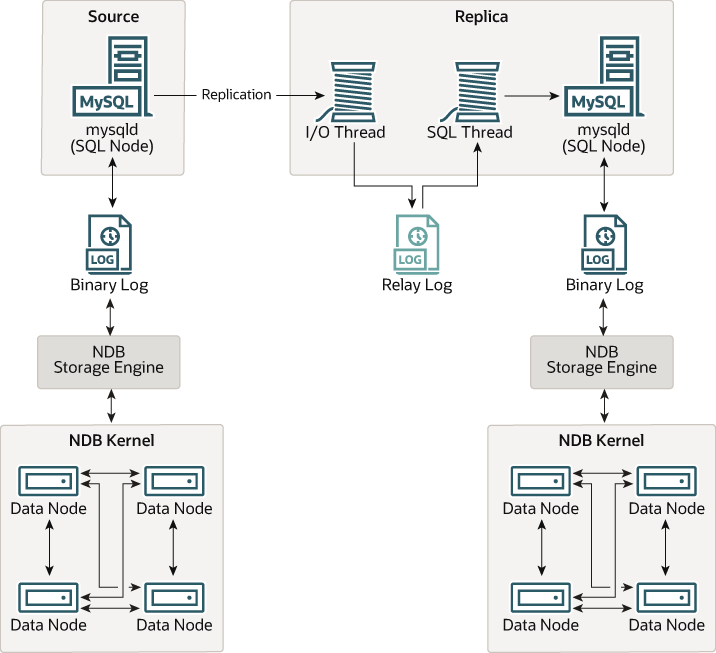
이 시나리오에서 복제 프로세스는 소스 클러스터의 연속적인 상태들을 기록하여 레플리카 클러스터에 저장하는 프로세스입니다. 이 프로세스는 NDB binary log injector 스레드라고 불리는 특수한 스레드에 의해 수행되며, 이 스레드는 각 MySQL 서버에서 실행되며 binary log(binlog)를 생성합니다.
이 스레드는 binary log를 생성하는 클러스터에서 발생하는 모든 변경 사항—MySQL Server를 통해 수행된 변경 사항만이 아니라—이 올바른 직렬화 순서로 binary log에 기록되도록 보장합니다. 우리는 MySQL 소스와 레플리카 서버를 복제 서버 또는 복제 노드라고 하고, 그들 사이의 데이터 흐름 또는 통신 라인을 복제 채널이라고 부릅니다.
NDB Cluster 및 NDB Cluster Replication으로 시점 복구를 수행하는 방법에 대한 정보는 Section 25.7.9.2, “Point-In-Time Recovery Using NDB Cluster Replication”을 참조하십시오.
NDB API replica status variable.
NDB API 카운터는 레플리카 클러스터에서 향상된 모니터링 기능을 제공할 수 있습니다. 이 카운터는 NDB 통계 _replica 상태 변수로 구현되며, SHOW STATUS의 출력이나 Performance Schema의 session_status 또는 global_status 테이블에 대한 쿼리 결과에서 확인할 수 있습니다.
이는 NDB Cluster Replication에서 레플리카 역할을 하는 MySQL Server에 연결된 mysql 클라이언트 세션에서 확인할 수 있습니다. 복제된 NDB 테이블에 영향을 미치는 문을 실행하기 전후의 이러한 상태 변수 값들을 비교함으로써, 레플리카가 NDB API 레벨에서 수행한 해당 작업을 관찰할 수 있으며, 이는 NDB Cluster Replication을 모니터링하거나 문제를 해결할 때 유용할 수 있습니다.
Section 25.6.14, “NDB API Statistics Counters and Variables”에서 추가 정보를 제공합니다.
Replication from NDB to non-NDB table.
NDB 테이블을 복제 소스 역할을 하는 NDB Cluster에서 InnoDB 또는 MyISAM과 같은 다른 MySQL 스토리지 엔진을 사용하는 테이블로 레플리카 mysqld에서 복제하는 것이 가능합니다. 이는 여러 조건에 따라 달라집니다.
자세한 내용은 Replication from NDB to other storage engines 및 Replication from NDB to a nontransactional storage engine을 참조하십시오.
25.6.19 NDB Cluster Security
25.7.1 NDB Cluster Replication: Abbreviations and Symbols