문서를 불러오는 중...
MySQL 9.5 Reference Manual 9.5의 25.7.10 NDB Cluster Replication: Bidirectional and Circular Replication의 한국어 번역본입니다.
아래의 경우에 피드백에서 신고해주신다면 반영하겠습니다.
감사합니다 :)
두 개의 클러스터 간에 양방향 복제를 위해, 그리고 임의 개수의 클러스터 간에 순환 복제를 위해 NDB Cluster를 사용하는 것이 가능합니다.
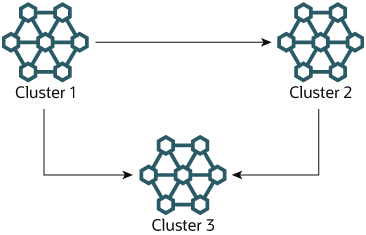
Circular replication 예시.
다음 몇 개의 단락에서는 1, 2, 3번으로 번호가 매겨진 세 개의 NDB Cluster가 포함된 복제 설정 예제를 살펴봅니다. 이 예제에서 Cluster 1은 Cluster 2의 복제 소스로, Cluster 2는 Cluster 3의 소스로, Cluster 3은 Cluster 1의 소스로 동작합니다. 각 클러스터에는 두 개의 SQL 노드가 있으며, SQL 노드 A와 B는 Cluster 1에, SQL 노드 C와 D는 Cluster 2에, SQL 노드 E와 F는 Cluster 3에 속합니다.
이러한 클러스터들을 사용한 순환 복제는 다음 조건들이 충족되는 한 지원됩니다:
모든 소스와 레플리카 상의 SQL 노드가 동일해야 합니다.
소스 및 레플리카로 동작하는 모든 SQL 노드는 시스템 변수 log_replica_updates가 활성화된 상태로 시작되어야 합니다.
이러한 유형의 순환 복제 설정은 다음 다이어그램과 같습니다:
Figure 25.14 NDB Cluster Circular Replication with All Sources As Replicas
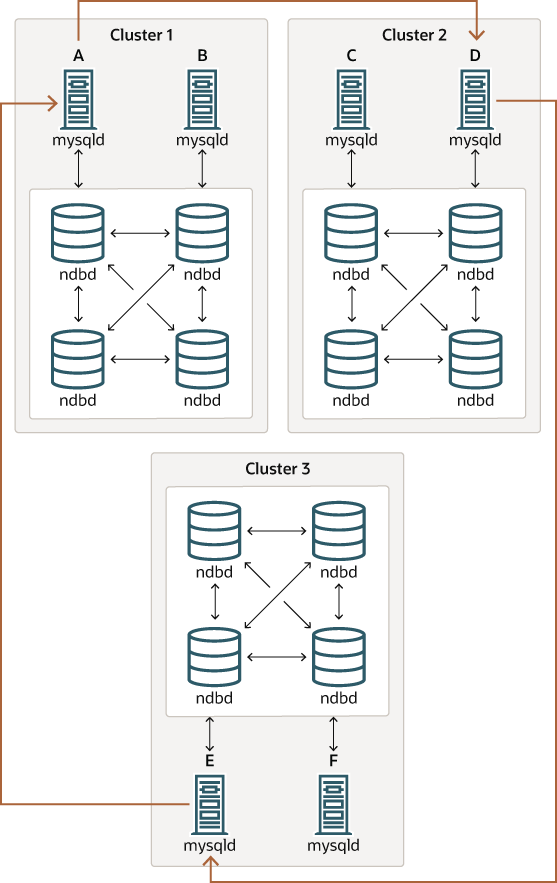
이 시나리오에서, Cluster 1의 SQL 노드 A는 Cluster 2의 SQL 노드 C에 복제를 수행하고, SQL 노드 C는 Cluster 3의 SQL 노드 E에, SQL 노드 E는 다시 SQL 노드 A에 복제를 수행합니다. 즉, (다이어그램의 곡선 화살표로 표시된) 복제 라인은 복제 소스 및 레플리카로 사용되는 모든 SQL 노드를 직접 연결합니다.
또한 다음과 같이 모든 소스 SQL 노드가 동시에 레플리카는 아니도록 순환 복제를 설정하는 것도 가능합니다:
Figure 25.15 NDB Cluster Circular Replication Where Not All Sources Are Replicas
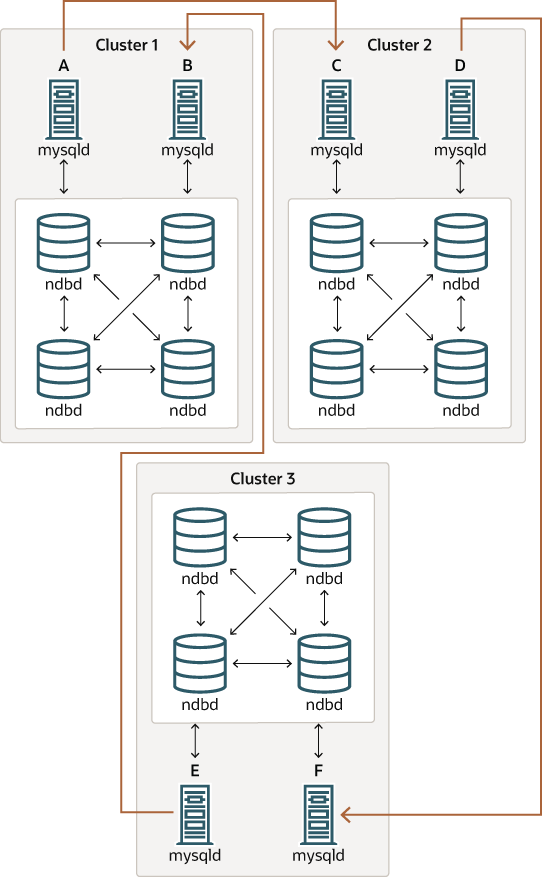
이 경우, 각 클러스터에서 서로 다른 SQL 노드들이 복제 소스와 레플리카로 사용됩니다. 어떤 SQL 노드도 시스템 변수 log_replica_updates가 활성화된 상태로 시작해서는 안 됩니다. 다이어그램에서 다시 곡선 화살표로 표시된 것처럼 복제 라인이 불연속적인 이러한 유형의 NDB Cluster 순환 복제 방식은 가능해야 하지만, 아직 충분히 테스트되지 않았으므로 여전히 실험적인 것으로 간주해야 합니다.
Replica 클러스터를 초기화하기 위해 NDB-native backup 및 restore 사용.
순환 복제를 설정할 때, 하나의 NDB Cluster에서 관리 클라이언트의 START BACKUP 명령을 사용해 백업을 생성한 후, 다른 NDB Cluster에서 ndb_restore를 사용하여 이 백업을 적용함으로써 레플리카 클러스터를 초기화할 수 있습니다. 이는 레플리카로 동작하는 두 번째 NDB Cluster의 SQL 노드에서 바이너리 로그를 자동으로 생성하지는 않습니다. 바이너리 로그가 생성되도록 하려면 해당 SQL 노드에서 SHOW TABLES 스테이트먼트를 실행해야 합니다. 이는 START REPLICA를 실행하기 전에 수행해야 합니다. 이는 알려진 이슈입니다.
Multi-source failover 예시.
이 섹션에서는 서버 ID가 1, 2, 3인 세 개의 NDB Cluster가 있는 멀티소스 NDB Cluster 복제 설정에서 장애 조치를 논의합니다. 이 시나리오에서 Cluster 1은 Cluster 2와 3으로 복제를 수행하고, Cluster 2 역시 Cluster 3으로 복제를 수행합니다. 이러한 관계는 다음과 같습니다:
Figure 25.16 NDB Cluster Multi-Source Replication With 3 Sources
즉, 데이터는 두 개의 서로 다른 경로(직접적으로와 Cluster 2를 경유하여)를 통해 Cluster 1에서 Cluster 3으로 복제됩니다.
멀티소스 복제에 참여하는 모든 MySQL 서버가 반드시 소스와 레플리카를 동시에 수행해야 하는 것은 아니며, 특정 NDB Cluster는 서로 다른 복제 채널에 대해 서로 다른 SQL 노드를 사용할 수 있습니다. 이러한 경우는 다음과 같습니다:
Figure 25.17 NDB Cluster Multi-Source Replication, With MySQL Servers
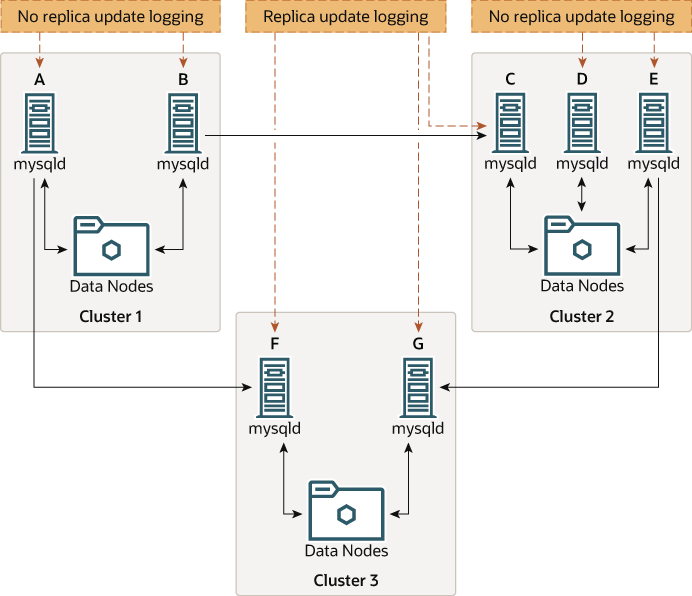
레플리카로 동작하는 MySQL 서버는 시스템 변수 log_replica_updates가 활성화된 상태로 실행되어야 합니다. 어떤 mysqld 프로세스에 이 옵션이 필요한지 역시 앞선 다이어그램에 표시되어 있습니다.
참고
log_replica_updates 시스템 변수를 사용하는 것은 레플리카로 실행되지 않는 서버에는 아무런 영향을 주지 않습니다.
장애 조치의 필요성은 복제 중인 클러스터 중 하나가 중단될 때 발생합니다. 이 예제에서는 Cluster 1이 서비스를 상실한 경우를 고려하며, 이로 인해 Cluster 3은 Cluster 1로부터의 두 개의 업데이트 소스를 잃게 됩니다. NDB Cluster 간 복제는 비동기식이므로, Cluster 3이 Cluster 1로부터 직접 받은 업데이트가 Cluster 2를 통해 받은 업데이트보다 더 최신이라는 보장은 없습니다.
이는 Cluster 1로부터의 업데이트와 관련하여 Cluster 3이 Cluster 2를 따라잡도록 함으로써 처리할 수 있습니다. MySQL 서버 관점에서는 MySQL 서버 C의 미처 반영되지 않은 업데이트를 서버 F로 복제해야 함을 의미합니다.
Server C에서 다음 쿼리를 수행합니다:
1mysqlC> SELECT @latest:=MAX(epoch) 2 -> FROM mysql.ndb_apply_status 3 -> WHERE server_id=1; 4 5mysqlC> SELECT 6 -> @file:=SUBSTRING_INDEX(File, '/', -1), 7 -> @pos:=Position 8 -> FROM mysql.ndb_binlog_index 9 -> WHERE orig_epoch >= @latest 10 -> AND orig_server_id = 1 11 -> ORDER BY epoch ASC LIMIT 1;
참고
이 쿼리의 성능을 향상시켜, 그에 따라 장애 조치 시간을 크게 단축하려면 ndb_binlog_index 테이블에 적절한 인덱스를 추가하면 됩니다. 자세한 내용은 Section 25.7.4, “NDB Cluster Replication Schema and Tables”를 참조하십시오.
Server C에서 server F로 @file 및 @pos 값을 수동으로 복사(또는 응용 프로그램이 이에 상응하는 작업을 수행하도록)합니다. 그런 다음 server F에서 다음 CHANGE REPLICATION SOURCE TO 스테이트먼트를 실행합니다:
1mysqlF> CHANGE REPLICATION SOURCE TO 2 -> SOURCE_HOST = 'serverC' 3 -> SOURCE_LOG_FILE='@file', 4 -> SOURCE_LOG_POS=@pos;
이 작업을 완료하면 MySQL 서버 F에서 START REPLICA 스테이트먼트를 실행할 수 있습니다. 그러면 server B에서 발생했으나 누락된 업데이트들이 server F로 복제됩니다.
CHANGE REPLICATION SOURCE TO 스테이트먼트는 또한 쉼표로 구분된 서버 ID 목록을 인수로 받아 해당 서버에서 발생한 이벤트를 무시하도록 하는 IGNORE_SERVER_IDS 옵션도 지원합니다. 이 스테이트먼트에 대한 문서와 함께, Section 15.7.7.36, “SHOW REPLICA STATUS Statement”도 참조하십시오. 이 옵션이 ndb_log_apply_status 변수와 어떻게 상호 작용하는지에 대한 정보는 Section 25.7.8, “Implementing Failover with NDB Cluster Replication”을 참조하십시오.
25.7.9 NDB Cluster Backups With NDB Cluster Replication
25.7.11 NDB Cluster Replication Using the Multithreaded Applier