문서를 불러오는 중...
MySQL 9.5 Reference Manual 9.5의 25.7.3 Known Issues in NDB Cluster Replication의 한국어 번역본입니다.
아래의 경우에 피드백에서 신고해주신다면 반영하겠습니다.
감사합니다 :)
이 섹션에서는 NDB Cluster에서 복제를 사용할 때 알려진 문제 또는 이슈들에 대해 설명합니다.
Loss of connection between source and replica.
연결 손실은 소스 클러스터의 SQL 노드와 레플리카 클러스터의 SQL 노드 사이에서 발생할 수도 있고, 소스 SQL 노드와 소스 클러스터의 데이터 노드 사이에서 발생할 수도 있습니다. 후자의 경우, 물리적 연결 손실(예: 네트워크 케이블 손상)의 결과일 뿐 아니라 데이터 노드 이벤트 버퍼의 오버플로로 인해 발생할 수도 있습니다. SQL 노드의 응답이 너무 느린 경우, 클러스터에 의해 제거될 수 있습니다(이는 MaxBufferedEpochs 및 TimeBetweenEpochs 구성 파라미터를 조정하여 어느 정도 제어할 수 있습니다). 이러한 일이 발생하면, 소스 SQL 노드의 바이너리 로그에 기록되지 않은 상태로 새로운 데이터가 소스 클러스터에 insert되는 것 이 전적으로 가능 합니다. 이러한 이유로, 고가용성을 보장하려면 백업 복제 채널을 유지하고, 1차 채널을 모니터링하며, 필요 시 레플리카 클러스터가 소스와 동기화된 상태를 유지하도록 2차 복제 채널로 장애 조치를 수행하는 것이 매우 중요합니다. NDB Cluster는 자체적으로 이러한 모니터링을 수행하도록 설계되지 않았으며, 이를 위해서는 외부 애플리케이션이 필요합니다.
소스 SQL 노드는 소스 클러스터에 연결 또는 재연결할 때 “gap” 이벤트를 발생시킵니다. (gap 이벤트는 “incident 이벤트”의 한 유형으로, 데이터베이스 내용에 영향을 주지만 변경 집합으로 쉽게 표현하기 어려운 incident가 발생했음을 나타냅니다. incident의 예로는 서버 장애, 데이터베이스 재동기화, 일부 소프트웨어 업데이트, 일부 하드웨어 변경 등이 있습니다.) 레플리카가 복제 로그에서 gap을 발견하면, 오류 메시지를 출력하고 멈춥니다. 이 메시지는 SHOW REPLICA STATUS 출력에서 확인할 수 있으며, 복제 스트림에 등록된 incident로 인해 SQL 스레드가 중지되었고 수동 개입이 필요함을 나타냅니다. 이러한 상황에서 해야 할 일에 대한 자세한 내용은 Section 25.7.8, “Implementing Failover with NDB Cluster Replication”을 참조하십시오.
주의
NDB Cluster는 복제 상태를 모니터링하거나 장애 조치를 제공하도록 자체적으로 설계되어 있지 않으므로, 레플리카 서버 또는 클러스터에 고가용성이 요구되는 경우, 반드시 여러 개의 복제 라인을 구성하고, 1차 복제 라인의 소스 [mysqld](https://dev.mysql.com/doc/refman/9.5/en/mysqld.html "6.3.1 mysqld — The MySQL Server)를 모니터링하며, 필요 시 2차 라인으로 장애 조치를 수행할 준비를 해야 합니다. 이는 수동으로 또는 서드파티 애플리케이션을 통해 수행해야 합니다. 이러한 유형의 구성을 구현하는 방법에 대한 정보는 Section 25.7.7, “Using Two Replication Channels for NDB Cluster Replication” 및 Section 25.7.8, “Implementing Failover with NDB Cluster Replication”을 참조하십시오.
standalone MySQL 서버에서 NDB Cluster로 복제하는 경우에는 일반적으로 하나의 채널이면 충분합니다.
Circular replication.
NDB Cluster Replication은 다음 예와 같이 순환 복제를 지원합니다. 복제 구성에는 1, 2, 3번으로 번호가 매겨진 세 개의 NDB Cluster가 포함되며, Cluster 1은 Cluster 2의 복제 소스로, Cluster 2는 Cluster 3의 소스로, Cluster 3는 Cluster 1의 소스로 동작하여 원형(circular)을 완성합니다. 각 NDB Cluster에는 두 개의 SQL 노드가 있으며, SQL 노드 A와 B는 Cluster 1에, SQL 노드 C와 D는 Cluster 2에, SQL 노드 E와 F는 Cluster 3에 속합니다.
이러한 클러스터를 사용한 순환 복제는 다음 조건이 충족되는 한 지원됩니다:
모든 소스 및 레플리카 클러스터의 SQL 노드가 동일해야 합니다.
소스 및 레플리카로 동작하는 모든 SQL 노드는 시스템 변수 log_replica_updates를 활성화하여 시작해야 합니다.
이러한 유형의 순환 복제 구성은 다음 다이어그램에 나와 있습니다:
Figure 25.11 NDB Cluster Circular Replication With All Sources As Replicas
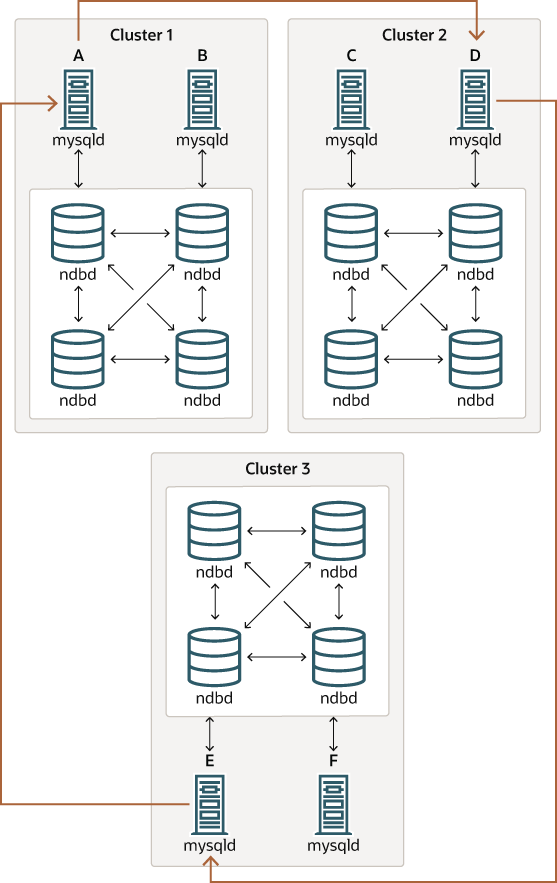
이 시나리오에서 Cluster 1의 SQL 노드 A는 Cluster 2의 SQL 노드 C에 복제하고, SQL 노드 C는 Cluster 3의 SQL 노드 E에 복제하며, SQL 노드 E는 SQL 노드 A에 복제합니다. 다시 말해, 다이어그램에서 곡선 화살표로 표시된 복제 라인은 소스 및 레플리카로 사용되는 모든 SQL 노드를 직접 연결합니다.
모든 소스 SQL 노드가 레플리카이기도 한 것은 아닌 순환 복제를 다음과 같이 설정하는 것도 가능합니다:
Figure 25.12 NDB Cluster Circular Replication Where Not All Sources Are Replicas
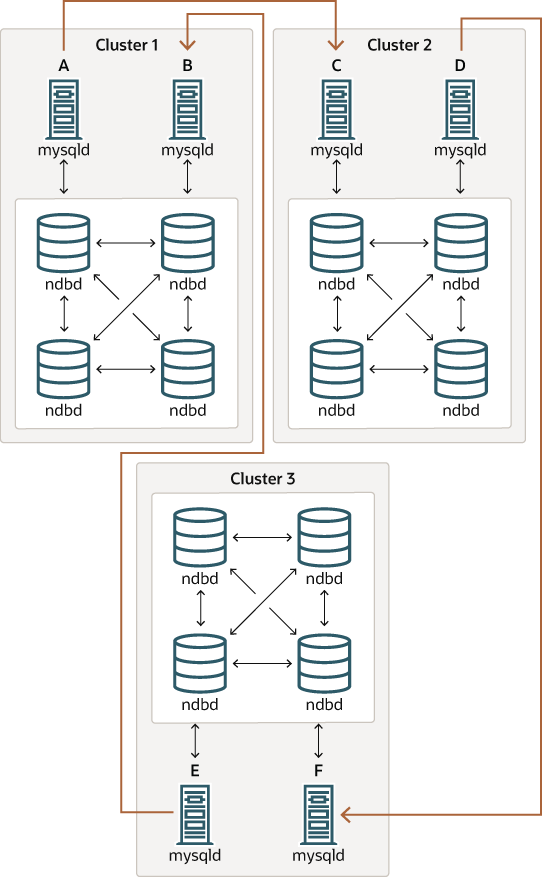
이 경우 각 클러스터에서 서로 다른 SQL 노드가 소스와 레플리카로 사용됩니다. 그러나 어떤 SQL 노드도 시스템 변수 log_replica_updates를 활성화한 상태로 시작해서는 안 됩니다. 다이어그램에서 역시 곡선 화살표로 표시된 복제 라인이 불연속적인 이러한 유형의 NDB Cluster 순환 복제 방식은 가능해야 하지만, 아직 충분히 테스트되지 않았으므로 여전히 실험적인 것으로 간주해야 합니다.
참고
NDB 스토리지 엔진은 idemponent 실행 모드를 사용하여, 그렇지 않으면 NDB Cluster의 순환 복제를 중단시킬 수 있는 중복 키 및 기타 에러를 억제합니다. 이는 시스템 변수 replica_exec_mode의 글로벌 값을 IDEMPOTENT로 설정하는 것과 동등하지만, NDB Cluster 복제에서는 필요하지 않습니다. 왜냐하면 NDB Cluster가 이 변수를 자동으로 설정하고, 이를 명시적으로 설정하려는 시도는 모두 무시하기 때문입니다.
NDB Cluster replication and primary keys.
노드 장애가 발생한 경우, 기본 키가 없는 NDB 테이블의 복제에서 여전히 오류가 발생할 수 있는데, 이러한 경우에는 중복 행이 insert될 가능성이 있기 때문입니다. 이러한 이유로, 복제되는 모든 NDB 테이블에 명시적인 기본 키를 두는 것이 강력히 권장됩니다.
NDB Cluster Replication and Unique Keys.
이전 버전의 NDB Cluster에서는 NDB 테이블의 유니크 키 컬럼 값을 업데이트하는 작업이 복제 시 중복 키 에러를 유발할 수 있었습니다. 이 문제는 유니크 키 체크를 모든 테이블 행 업데이트가 완료된 후까지 지연(defer)함으로써, NDB 테이블 간 복제에 대해서는 해결되었습니다.
이러한 방식의 제약 지연은 현재 NDB에서만 지원됩니다. 따라서 NDB에서 InnoDB나 MyISAM 같은 다른 스토리지 엔진으로의 복제에서 유니크 키 업데이트를 수행하는 것은 여전히 지원되지 않습니다.
지연 체크 없이 유니크 키 업데이트를 복제할 때 발생하는 문제는, 소스에서 다음과 같이 생성 및 데이터가 채워지고, 유니크 키 업데이트를 지연하지 않는 레플리카로 전송되는 NDB 테이블 t를 사용하여 설명할 수 있습니다:
CREATE TABLE t ( p INT PRIMARY KEY, c INT, UNIQUE KEY u (c) ) ENGINE NDB;
INSERT INTO t VALUES (1,1), (2,2), (3,3), (4,4), (5,5);
t에 대해 다음 UPDATE 문을 실행하면, ORDER BY 옵션이 전체 테이블에 대해 수행되므로, 영향을 받는 행들이 그 순서대로 처리되어 소스에서는 성공합니다:
UPDATE t SET c = c - 1 ORDER BY p;
동일한 문은 레플리카에서는 실패하며, 중복 키 에러나 다른 제약 위반이 발생합니다. 그 이유는 행 업데이트의 정렬이 테이블 전체가 아니라 하나의 파티션 단위로 수행되기 때문입니다.
참고
모든 NDB 테이블은 생성 시 암묵적으로 키 기준으로 파티셔닝됩니다. 자세한 내용은 Section 26.2.5, “KEY Partitioning”을 참조하십시오.
GTIDs not supported.
글로벌 트랜잭션 ID를 사용하는 복제는 NDB 스토리지 엔진과 호환되지 않으며 지원되지 않습니다. GTID를 활성화하면 NDB Cluster Replication이 실패할 가능성이 큽니다.
Restarting with --initial.
클러스터를 --initial 옵션과 함께 재시작하면 GCI와 epoch 번호의 시퀀스가 0부터 다시 시작됩니다. (이는 일반적으로 NDB Cluster 전체에 해당하는 사항이며, 클러스터를 포함한 복제 시나리오로만 한정되지 않습니다.) 이 경우 복제에 관여하는 MySQL 서버도 재시작해야 합니다. 그 후 RESET BINARY LOGS AND GTIDS 및 RESET REPLICA 문을 사용하여 각각 잘못된 ndb_binlog_index 및 ndb_apply_status 테이블을 초기화해야 합니다.
Replication from NDB to other storage engines.
소스의 NDB 테이블을 레플리카에서 다른 스토리지 엔진을 사용하는 테이블로 복제하는 것이 가능하지만, 여기 나열된 제약을 고려해야 합니다:
멀티 소스 및 순환 복제는 지원되지 않습니다(이 기능이 동작하려면 소스와 레플리카의 테이블 모두 NDB 스토리지 엔진을 사용해야 합니다).
레플리카의 테이블에 대해 자체적으로 바이너리 로깅을 수행하지 않는 스토리지 엔진을 사용하는 경우에는 특별한 처리가 필요합니다.
레플리카의 테이블에 대해 비트랜잭션 스토리지 엔진을 사용하는 경우에도 특별한 처리가 필요합니다.
소스 [mysqld](https://dev.mysql.com/doc/refman/9.5/en/mysqld.html "6.3.1 mysqld — The MySQL Server)는 --ndb-log-update-as-write=0 또는 --ndb-log-update-as-write=OFF 옵션을 사용하여 시작해야 합니다.
다음 몇 개의 단락에서는 방금 설명한 각 이슈에 대한 추가 정보를 제공합니다.
Multiple sources not supported when replicating NDB to other storage engines.
NDB에서 다른 스토리지 엔진으로 복제할 때 두 데이터베이스 간의 관계는 일대일이어야 합니다. 이는 NDB Cluster와 다른 스토리지 엔진 간의 양방향 또는 순환 복제는 지원되지 않음을 의미합니다.
또한, NDB와 다른 스토리지 엔진 간의 복제에서는 둘 이상의 복제 채널을 구성할 수 없습니다. (NDB Cluster 데이터베이스는 동시에 여러 NDB Cluster 데이터베이스로 복제할 수 있습니다.) 소스에서 NDB 테이블을 사용하는 경우에도, 여러 MySQL 서버가 모든 변경 사항에 대한 바이너리 로그를 유지하는 것은 여전히 가능하지만, 레플리카가 소스를 변경(장애 조치)하려면 새로운 소스-레플리카 관계를 레플리카에서 명시적으로 정의해야 합니다.
Replicating NDB tables to a storage engine that does not perform binary logging.
NDB Cluster에서 자체적으로 바이너리 로깅을 처리하지 않는 스토리지 엔진을 사용하는 레플리카로 복제를 시도하면, 복제 프로세스는 다음과 같은 에러와 함께 중단됩니다:
Binary logging not possible ... Statement cannot be
written atomically since more than one engine involved and at
least one engine is self-logging (Error
1595).
이 문제는 다음 중 한 가지 방법으로 우회할 수 있습니다:
레플리카에서 바이너리 로깅을 끕니다.
이는 sql_log_bin = 0을 설정하여 수행할 수 있습니다.
mysql.ndb_apply_status 테이블에 사용하는 스토리지 엔진을 변경합니다.
이 테이블에 대해 자체적으로 바이너리 로깅을 처리하지 않는 엔진을 사용하도록 하면 충돌을 제거할 수 있습니다. 이는 레플리카에서 ALTER TABLE mysql.ndb_apply_status ENGINE=MyISAM과 같은 문을 실행하여 수행할 수 있습니다. 레플리카에서 NDB 이외의 스토리지 엔진을 사용할 때는 여러 레플리카 간 동기화 유지에 대해 걱정할 필요가 없으므로, 이렇게 하는 것이 안전합니다.
레플리카에서 mysql.ndb_apply_status 테이블에 대한 변경 사항을 필터링합니다.
이는 레플리카를 --replicate-ignore-table=mysql.ndb_apply_status와 함께 시작하여 수행할 수 있습니다. 복제에서 다른 테이블도 무시해야 한다면, 적절한 --replicate-wild-ignore-table 옵션을 대신 사용하는 것이 좋을 수 있습니다.
주의
한 NDB Cluster에서 다른 NDB Cluster로 복제하는 경우에는 mysql.ndb_apply_status의 복제 또는 바이너리 로깅을 비활성화하거나 이 테이블에 사용하는 스토리지 엔진을 변경해서는 안 됩니다. 자세한 내용은 Replication and binary log filtering rules with replication between NDB Clusters을 참조하십시오.
Replication from NDB to a nontransactional storage engine.
NDB에서 MyISAM과 같은 비트랜잭션 스토리지 엔진으로 복제할 때, INSERT ... ON DUPLICATE KEY UPDATE 문을 복제하는 중에 불필요한 중복 키 에러가 발생할 수 있습니다. 이는 --ndb-log-update-as-write=0를 사용하여 억제할 수 있으며, 이 옵션은 업데이트를 업데이트가 아닌 쓰기로 로깅하도록 강제합니다.
NDB Replication and File System Encryption (TDE).
암호화된 파일시스템을 사용하는 것은 NDB Replication에 아무런 영향을 주지 않습니다. 다음과 같은 모든 시나리오가 지원됩니다:
암호화된 파일시스템을 사용하는 NDB Cluster에서, 파일시스템이 암호화되지 않은 NDB Cluster로의 복제.
파일시스템이 암호화되지 않은 NDB Cluster에서, 파일시스템이 암호화된 NDB Cluster로의 복제.
파일시스템이 암호화된 NDB Cluster에서, 암호화되지 않은 InnoDB 테이블을 사용하는 standalone MySQL 서버로의 복제.
파일시스템이 암호화되지 않은 NDB Cluster에서, 파일시스템 암호화가 적용된 InnoDB 테이블을 사용하는 standalone MySQL 서버로의 복제.
Replication and binary log filtering rules with replication between NDB Clusters.
복제되는 데이터베이스나 테이블을 필터링하기 위해 --replicate-do-*, --replicate-ignore-*, --binlog-do-db, --binlog-ignore-db 중 어떤 옵션이라도 사용 중이라면, 복제가 올바르게 동작하는 데 필요한 mysql.ndb_apply_status의 복제 또는 바이너리 로깅이 차단되지 않도록 주의해야 합니다. 특히 다음 사항을 염두에 두어야 합니다:
--replicate-do-db=db_name (그리고 다른 --replicate-do-* 또는 --replicate-ignore-* 옵션 없음)을 사용하면, 데이터베이스 db_name 내의 테이블만이 오직 복제됩니다. 이 경우, 레플리카에 mysql.ndb_apply_status가 채워지도록 하기 위해 --replicate-do-db=mysql, --binlog-do-db=mysql, 또는 --replicate-do-table=mysql.ndb_apply_status도 함께 사용해야 합니다.
--binlog-do-db=db_name (그리고 다른 --binlog-do-db 옵션 없음)을 사용하면, 데이터베이스 db_name 내의 테이블에 대한 변경 사항만이 오직 바이너리 로그에 기록됩니다. 이 경우에도 레플리카에 mysql.ndb_apply_status가 채워지도록 하기 위해 --replicate-do-db=mysql, --binlog-do-db=mysql, 또는 --replicate-do-table=mysql.ndb_apply_status도 함께 사용해야 합니다.
--replicate-ignore-db=mysql를 사용하면 mysql 데이터베이스 내의 어떤 테이블도 복제되지 않습니다. 이 경우, mysql.ndb_apply_status가 복제되도록 하기 위해 --replicate-do-table=mysql.ndb_apply_status도 함께 사용해야 합니다.
--binlog-ignore-db=mysql를 사용하면, mysql 데이터베이스 내의 테이블에 대한 변경 사항은 바이너리 로그에 기록되지 않습니다. 이 경우에도 mysql.ndb_apply_status가 복제되도록 하기 위해 --replicate-do-table=mysql.ndb_apply_status을 함께 사용해야 합니다.
또한 각 복제 규칙은 다음 사항을 요구함을 기억해야 합니다:
자체적인 --replicate-do-* 또는 --replicate-ignore-* 옵션이 필요하며, 여러 규칙을 하나의 복제 필터링 옵션으로 표현할 수 없습니다. 이러한 규칙에 대한 정보는 Section 19.1.6, “Replication and Binary Logging Options and Variables”을 참조하십시오.
자체적인 --binlog-do-db 또는 --binlog-ignore-db 옵션이 필요하며, 여러 규칙을 하나의 바이너리 로그 필터링 옵션으로 표현할 수 없습니다. 이러한 규칙에 대한 정보는 Section 7.4.4, “The Binary Log”를 참조하십시오.
NDB Cluster에서 NDB가 아닌 스토리지 엔진을 사용하는 레플리카로 복제하는 경우에는, 방금 설명한 고려 사항들이 이 섹션의 다른 부분에서 논의된 것처럼 적용되지 않을 수도 있습니다.
NDB Cluster Replication and IPv6.
모든 유형의 NDB Cluster 노드는 NDB 9.5에서 IPv6를 지원합니다. 여기에는 매니지먼트 노드, 데이터 노드, 그리고 API 또는 SQL 노드가 포함됩니다.
참고
NDB 9.5에서는 어떤 NDB Cluster 노드에도 IPv6 주소를 사용하지 않을 계획이라면, Linux 커널에서 IPv6 지원을 비활성화할 수 있습니다.
Attribute promotion and demotion.
NDB Cluster Replication은 attribute promotion 및 demotion을 지원합니다. demotion 구현은 손실 변환과 비손실 타입 변환을 구분하며, 레플리카에서 이들의 사용 여부는 시스템 변수 replica_type_conversions의 글로벌 값을 설정하여 제어할 수 있습니다.
NDB Cluster에서 attribute promotion 및 demotion에 대한 자세한 내용은 Row-based replication: attribute promotion and demotion을 참조하십시오.
NDB는 InnoDB나 MyISAM와 달리 virtual column에 대한 변경 사항을 바이너리 로그에 기록하지 않습니다. 그러나 이는 NDB Cluster Replication이나 NDB와 다른 스토리지 엔진 간의 복제에 부정적인 영향을 주지 않습니다. stored generated column에 대한 변경 사항은 로그에 기록됩니다.
25.7.2 General Requirements for NDB Cluster Replication
25.7.4 NDB Cluster Replication Schema and Tables