문서를 불러오는 중...
MySQL 9.5 Reference Manual 9.5의 25.7.4 NDB Cluster Replication Schema and Tables의 한국어 번역본입니다.
아래의 경우에 피드백에서 신고해주신다면 반영하겠습니다.
감사합니다 :)
NDB Cluster의 복제는 복제 중인 클러스터와 replica 양쪽에서 SQL 노드로 동작하는 각 MySQL Server 인스턴스의 mysql 데이터베이스에 있는 여러 전용 테이블을 사용합니다. 이는 replica가 단일 서버인지 또는 클러스터인지는 관계없이 항상 적용됩니다.
ndb_binlog_index와 ndb_apply_status 테이블은 mysql 데이터베이스에 생성됩니다. 이들 테이블은 사용자가 명시적으로 복제하지 않아야 합니다. 두 테이블 모두 NDB 바이너리 로그 (binlog) 인젝터 스레드에 의해 유지 관리되므로, 이를 생성하거나 유지하기 위해 일반적으로 사용자의 개입이 필요하지 않습니다. 이는 소스 mysqld 프로세스가 NDB 스토리지 엔진에 의해 수행된 변경 사항으로 갱신되도록 해 줍니다. NDB binlog 인젝터 스레드는 NDB 스토리지 엔진으로부터 직접 이벤트를 수신합니다. NDB 인젝터는 클러스터 내 모든 데이터 이벤트를 캡처할 책임이 있으며, 데이터의 변경, insert 또는 delete를 발생시키는 모든 이벤트가 ndb_binlog_index 테이블에 기록되도록 보장합니다. replica I/O (receiver) 스레드는 소스의 바이너리 로그에 있는 이벤트를 replica의 릴레이 로그로 전송합니다.
ndb_replication 테이블은 수동으로 생성해야 합니다. 이 테이블은 사용자가 업데이트하여 데이터베이스 또는 테이블 단위의 필터링을 수행할 수 있습니다. 자세한 내용은 ndb_replication Table을 참조하십시오. ndb_replication은 또한 NDB 복제 conflict detection 및 resolution에서 conflict resolution control을 위해 사용됩니다. 이에 대해서는 Conflict Resolution Control을 참조하십시오.
ndb_binlog_index와 ndb_apply_status가 자동으로 생성되고 유지 관리되기는 하지만, NDB Cluster를 복제용으로 준비하는 초기 단계에서 이들 테이블의 존재 여부와 무결성을 확인하는 것이 좋습니다. 소스에서 mysql.ndb_binlog_index 테이블을 직접 조회하여 바이너리 로그에 기록된 이벤트 데이터를 확인할 수 있습니다. 이는 SHOW BINLOG EVENTS 문을 사용하여 소스 또는 replica SQL 노드 어느 쪽에서든 수행할 수도 있습니다. (자세한 내용은 Section 15.7.7.3, “SHOW BINLOG EVENTS Statement”를 참조하십시오.)
SHOW ENGINE NDB STATUS의 출력에서도 유용한 정보를 얻을 수 있습니다.
참고
NDB 테이블에 대해 스키마 변경을 수행할 때, 애플리케이션은 해당 문을 실행한 MySQL 클라이언트 커넥션에서 ALTER TABLE 문이 반환될 때까지, 업데이트된 테이블 정의를 사용하려고 시도해서는 안 됩니다.
ndb_apply_status는 소스에서 replica로 복제된 작업을 기록하는 데 사용됩니다. ndb_apply_status 테이블이 replica에 존재하지 않으면, ndb_restore가 이를 다시 생성합니다.
ndb_binlog_index의 경우와는 달리, 이 테이블의 데이터는 (replica) 클러스터의 특정 SQL 노드에 종속되지 않으므로 ndb_apply_status는 다음 예시와 같이 NDBCLUSTER 스토리지 엔진을 사용할 수 있습니다:
1CREATE TABLE `ndb_apply_status` ( 2 `server_id` INT(10) UNSIGNED NOT NULL, 3 `epoch` BIGINT(20) UNSIGNED NOT NULL, 4 `log_name` VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL, 5 `start_pos` BIGINT(20) UNSIGNED NOT NULL, 6 `end_pos` BIGINT(20) UNSIGNED NOT NULL, 7 PRIMARY KEY (`server_id`) USING HASH 8) ENGINE=NDBCLUSTER DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
ndb_apply_status 테이블은 replica에서만 채워지므로, 소스에서는 이 테이블에 row가 전혀 존재하지 않습니다. 따라서 소스에서는 ndb_apply_status에 대해 어떤 DataMemory를 할당할 필요가 없습니다.
이 테이블은 소스에서 발생한 데이터로 채워지므로, 복제를 허용해야 합니다. replica가 ndb_apply_status를 업데이트하지 못하게 하거나, 소스가 바이너리 로그에 기록하지 못하도록 하는 복제 필터링 또는 바이너리 로그 필터링 규칙은 클러스터 간 복제가 정상적으로 동작하지 못하게 만들 수 있습니다. 이러한 필터링 규칙으로 인해 발생할 수 있는 잠재적 문제에 대한 자세한 내용은 Replication and binary log filtering rules with replication between NDB Clusters를 참조하십시오.
이 테이블을 삭제할 수는 있지만, 권장되지 않습니다. 이를 삭제하면 모든 SQL 노드가 read-only 모드로 전환됩니다. NDB는 이 테이블이 drop된 것을 감지하고 다시 생성하며, 그 후 다시 update를 수행할 수 있게 됩니다. ndb_apply_status를 drop하고 재생성하면 바이너리 로그에 gap 이벤트가 생성되며, 이 gap 이벤트는 복제 채널이 재시작될 때까지 replica SQL 노드가 소스에서 오는 변경 사항 적용을 중지하게 만듭니다.
이 테이블의 epoch 컬럼에 0이 있으면, 이는 NDB가 아닌 다른 스토리지 엔진에서 시작된 트랜잭션을 의미합니다.
ndb_apply_status는 upstream 소스로부터 replica 클러스터에 복제 및 적용된 epoch 트랜잭션을 기록하는 데 사용됩니다. 이 정보는 NDB 온라인 백업에 캡처되지만, 설계상 ndb_restore에 의해 복원되지는 않습니다. 어떤 경우에는 새로운 환경 구성에 이 정보를 복원하는 것이 도움이 될 수 있으며, 이때는 --with-apply-status 옵션과 함께 ndb_restore를 호출하면 됩니다. 자세한 내용은 해당 옵션 설명을 참고하십시오.
NDB Cluster 복제는 바이너리 로그의 인덱싱 데이터를 저장하기 위해 ndb_binlog_index 테이블을 사용합니다. 이 테이블은 각 MySQL 서버에 로컬하며 클러스터링에 참여하지 않으므로 InnoDB 스토리지 엔진을 사용합니다. 이는 소스 클러스터에 참여하는 각 mysqld에서 이 테이블을 개별적으로 생성해야 함을 의미합니다. (바이너리 로그 자체는 클러스터 내 모든 MySQL 서버로부터의 update를 포함합니다.) 이 테이블은 다음과 같이 정의됩니다:
1CREATE TABLE `ndb_binlog_index` ( 2 `Position` BIGINT(20) UNSIGNED NOT NULL, 3 `File` VARCHAR(255) NOT NULL, 4 `epoch` BIGINT(20) UNSIGNED NOT NULL, 5 `inserts` INT(10) UNSIGNED NOT NULL, 6 `updates` INT(10) UNSIGNED NOT NULL, 7 `deletes` INT(10) UNSIGNED NOT NULL, 8 `schemaops` INT(10) UNSIGNED NOT NULL, 9 `orig_server_id` INT(10) UNSIGNED NOT NULL, 10 `orig_epoch` BIGINT(20) UNSIGNED NOT NULL, 11 `gci` INT(10) UNSIGNED NOT NULL, 12 `next_position` bigint(20) unsigned NOT NULL, 13 `next_file` varchar(255) NOT NULL, 14 PRIMARY KEY (`epoch`,`orig_server_id`,`orig_epoch`) 15) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
참고
이전 릴리스에서 업그레이드하는 경우, MySQL 업그레이드 절차를 수행하고 MySQL 서버를 --upgrade=FORCE 옵션과 함께 시작하여 시스템 테이블이 업그레이드되었는지 확인해야 합니다. 시스템 테이블 업그레이드는 이 테이블에 대해 ALTER TABLE ... ENGINE=INNODB 문이 실행되도록 합니다. 이 테이블에서 MyISAM 스토리지 엔진 사용은 하위 호환성을 위해 계속 지원됩니다.
ndb_binlog_index는 InnoDB로 변환된 후 추가적인 디스크 공간을 필요로 할 수 있습니다. 이 문제가 되는 경우, 이 테이블에 대해 InnoDB 테이블스페이스를 사용하거나 ROW_FORMAT을 COMPRESSED로 변경하거나, 또는 두 가지를 모두 사용하여 공간을 절약할 수 있습니다. 자세한 내용은 Section 15.1.25, “CREATE TABLESPACE Statement” 및 Section 15.1.24, “CREATE TABLE Statement”, 그리고 Section 17.6.3, “Tablespaces”를 참조하십시오.
ndb_binlog_index 테이블의 크기는 각 바이너리 로그 파일당 epoch 수와 바이너리 로그 파일 수에 따라 달라집니다. 한 바이너리 로그 파일당 epoch 수는 일반적으로 epoch당 생성되는 바이너리 로그 양과 바이너리 로그 파일의 크기에 따라 달라지며, epoch가 작을수록 파일당 epoch 수가 많아집니다. empty epoch는 --ndb-log-empty-epochs 옵션이 OFF인 경우에도 ndb_binlog_index 테이블에 insert를 발생시킨다는 점에 유의해야 합니다. 즉, 파일당 entry 수는 해당 파일이 사용되는 시간 길이에 따라 달라지며, 이 관계는 다음과 같은 공식으로 표현할 수 있습니다:
1[number of epochs per file] = [time spent per file] / TimeBetweenEpochs
부하가 많은 NDB Cluster는 바이너리 로그에 정기적으로 기록하며, 조용한 클러스터보다 바이너리 로그 파일을 더 자주 rotate하는 경향이 있습니다. 이는 --ndb-log-empty-epochs=ON을 사용한 “조용한” NDB Cluster가, activity가 많은 클러스터보다 파일당 훨씬 더 많은 ndb_binlog_index row를 가질 수 있음을 의미합니다.
mysqld를 --ndb-log-orig 옵션과 함께 시작하면, orig_server_id와 orig_epoch 컬럼은 각각 이벤트가 발생한 서버의 ID와 그 서버에서 이벤트가 발생한 epoch를 저장하며, 이는 여러 소스를 사용하는 NDB Cluster 복제 구성에서 유용합니다. multi-source 구성에서 replica에서 적용된 가장 높은 epoch에 가장 근접한 바이너리 로그 위치를 찾는 데 사용되는 SELECT 문은 (자세한 내용은 Section 25.7.10, “NDB Cluster Replication: Bidirectional and Circular Replication” 참조) 인덱스가 없는 이 두 컬럼을 사용합니다. 이는 특히 소스가 --ndb-log-empty-epochs=ON와 함께 실행되었을 때, failover를 시도할 때 쿼리가 테이블 스캔을 수행해야 하므로 성능 문제를 일으킬 수 있습니다. 다음과 같이 이 컬럼에 인덱스를 추가하여 multi-source failover 시간을 개선할 수 있습니다:
1ALTER TABLE mysql.ndb_binlog_index 2 ADD INDEX orig_lookup USING BTREE (orig_server_id, orig_epoch);
이 인덱스를 추가하는 것은 단일 소스에서 단일 replica로 복제하는 경우에는 효과가 없습니다. 이러한 경우 바이너리 로그 위치를 얻기 위해 사용하는 쿼리는 orig_server_id나 orig_epoch를 전혀 사용하지 않기 때문입니다.
next_position 및 next_file 컬럼 사용에 대한 자세한 내용은 Section 25.7.8, “Implementing Failover with NDB Cluster Replication”을 참조하십시오.
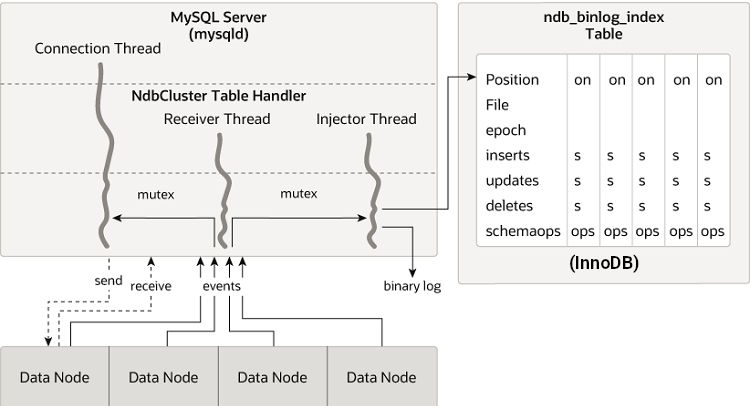
다음 그림은 NDB Cluster 복제 소스 서버, 그 바이너리 로그 인젝터 스레드, 그리고 mysql.ndb_binlog_index 테이블의 관계를 보여 줍니다.
Figure 25.13 The Replication Source Cluster
ndb_replication 테이블은 바이너리 로깅과 conflict resolution을 제어하는 데 사용되며, 테이블 단위로 동작합니다. 이 테이블의 각 row는 복제 대상 테이블 하나에 해당하며, 해당 테이블에 대한 변경 사항을 어떻게 로그할지 결정하고, conflict resolution function이 지정된 경우 그 테이블에 대한 conflict를 어떻게 해결할지를 결정합니다.
ndb_apply_status 및 ndb_replication 테이블과는 달리, ndb_replication 테이블은 다음에 보이는 SQL 문을 사용하여 수동으로 생성해야 합니다:
1CREATE TABLE mysql.ndb_replication ( 2 db VARBINARY(63), 3 table_name VARBINARY(63), 4 server_id INT UNSIGNED, 5 binlog_type INT UNSIGNED, 6 binlog_row_slice_count UNSIGNED, 7 binlog_row_slice_id UNSIGNED, 8 conflict_fn VARBINARY(128), 9 PRIMARY KEY USING HASH (db, table_name, server_id) 10) ENGINE=NDB 11PARTITION BY KEY(db,table_name);
이 테이블의 컬럼은 다음과 같으며, 각 컬럼에 대한 설명은 다음과 같습니다:
db 컬럼복제 대상 테이블이 포함된 데이터베이스의 이름입니다.
데이터베이스 이름의 일부로 와일드카드인 _ 및 % 중 하나 또는 둘 다를 사용할 수 있습니다. (이 섹션의 뒷부분에 나오는 Matching with wildcards를 참조하십시오.)
table_name 컬럼복제 대상 테이블의 이름입니다.
테이블 이름에는 와일드카드인 _ 및 % 중 하나 또는 둘 다를 포함할 수 있습니다. 자세한 내용은 이 섹션의 뒷부분에 나오는 Matching with wildcards를 참조하십시오.
server_id 컬럼테이블이 위치한 MySQL 인스턴스(SQL 노드)의 고유한 서버 ID입니다.
이 컬럼의 0은 %와 동등한 와일드카드처럼 동작하며, 어떤 서버 ID와도 일치합니다. (자세한 내용은 이 섹션의 뒷부분에 나오는 Matching with wildcards를 참조하십시오.)
binlog_type 컬럼사용할 바이너리 로깅 유형입니다. 값과 설명은 본문을 참조하십시오.
binlog_row_slice_count 컬럼바이너리 로그를 분할할 slice 수입니다. 이 테이블에 대해 slicing을 사용하지 않는 경우 1이며, 0은 무시되므로 사실상 1과 동일하게 동작합니다.
binlog_row_slice_id 컬럼이 서버가 로그할 slice의 ID입니다. 이 테이블에 대해 slicing을 사용하지 않는 경우 0입니다.
conflict_fn 컬럼적용할 conflict resolution function입니다. 다음 중 하나입니다: NDB$OLD(), NDB$MAX(), NDB$MAX_DELETE_WIN(), NDB$EPOCH(), NDB$EPOCH_TRANS(), NDB$EPOCH2(), NDB$EPOCH2_TRANS() NDB$MAX_INS(), 또는 NDB$MAX_DEL_WIN_INS(); NULL은 이 테이블에 대해 conflict resolution을 사용하지 않음을 의미합니다.
이러한 function과 NDB 복제 conflict resolution에서의 사용 방법에 대한 자세한 내용은 Conflict Resolution Functions를 참조하십시오.
일부 conflict resolution function (NDB$OLD(), NDB$EPOCH(), NDB$EPOCH_TRANS())은 하나 이상의 사용자가 생성한 exceptions 테이블 사용을 필요로 합니다. 이에 대해서는 Conflict Resolution Exceptions Table을 참조하십시오.
NDB 복제에서 conflict resolution을 활성화하려면, conflict를 해결할 SQL 노드(또는 여러 노드)에 이 테이블을 생성하고 control 정보를 채워 넣어야 합니다. 사용하려는 conflict resolution 유형 및 방법에 따라, 이는 소스, replica, 또는 두 서버 모두가 될 수 있습니다. 데이터가 replica에서 로컬로도 변경될 수 있는 단순한 소스-replica 구성에서는 일반적으로 replica 쪽에서 이를 수행합니다. bidirectional 복제와 같은 더 복잡한 복제 구성에서는 관련된 모든 소스에서 이를 수행하는 것이 일반적입니다. 자세한 내용은 Section 25.7.12, “NDB Cluster Replication Conflict Resolution”을 참조하십시오.
ndb_replication 테이블은 conflict resolution 범위 밖에서도 테이블 수준의 바이너리 로깅 제어를 허용하며, 이 경우 conflict_fn은 NULL로 지정되고 나머지 컬럼 값이 특정 테이블 또는 와일드카드 표현식과 일치하는 여러 테이블에 대한 바이너리 로깅을 제어하는 데 사용됩니다. binlog_type 컬럼에 적절한 값을 설정하면, 특정 테이블 또는 테이블 집합의 로깅이 원하는 바이너리 로그 포맷을 사용하도록 하거나, 바이너리 로깅을 완전히 비활성화할 수 있습니다. 이 컬럼에 대한 가능한 값과 값 설명은 다음 표에 나와 있습니다:
Table 25.42 binlog_type values, with values and descriptions
| Value | Description |
|---|---|
| 0 | 서버 기본값 사용 |
| 1 | 이 테이블을 바이너리 로그에 기록하지 않음 (하나 이상의 특정 테이블에만 적용된다는 점을 제외하면<br> sql_log_bin = 0과 동일한 효과) |
| 2 | 업데이트된 속성만 로그하며, 이를 WRITE_ROW<br> 이벤트로 로그 |
| 3 | 업데이트되지 않은 경우에도 full row를 로그 (MySQL 서버 기본 동작) |
| 6 | 값이 변경되지 않았더라도 업데이트된 속성을 사용 |
| 7 | 값이 변경되지 않았더라도 full row를 로그하며, update를<br> UPDATE_ROW 이벤트로 로그 |
| 8 | update를 UPDATE_ROW로 로그하고, before image에서는 primary key<br> 컬럼만 로그하며, after image에서는 업데이트된 컬럼만 로그 (하나 이상의 특정 테이블에만 적용된다는 점을 제외하면<br> --ndb-log-update-minimal과 동일한 효과) |
| 9 | update를 UPDATE_ROW로 로그하고, before image에서는 primary key<br> 컬럼만 로그하며, after image에서는 primary key 컬럼을 제외한 모든 컬럼을 로그 |
참고
binlog_type 값 4와 5는 사용되지 않으므로, 방금 제시한 표와 다음 표 모두에서 생략되었습니다.
몇몇 binlog_type 값은 mysqld 로깅 옵션인 --ndb-log-updated-only, --ndb-log-update-as-write, --ndb-log-update-minimal의 다양한 조합과 동일합니다. 다음 표는 이를 보여 줍니다:
Table 25.43 binlog_type values with equivalent combinations of NDB logging options
| Value | --ndb-log-updated-only Value | --ndb-log-update-as-write Value | --ndb-log-update-minimal Value |
|---|---|---|---|
| 0 | -- | -- | -- |
| 1 | -- | -- | -- |
| 2 | ON | ON | OFF |
| 3 | OFF | ON | OFF |
| 6 | ON | OFF | OFF |
| 7 | OFF | OFF | OFF |
| 8 | ON | OFF | ON |
| 9 | OFF | OFF | ON |
적절한 db, table_name, binlog_type 컬럼 값을 사용하여 ndb_replication 테이블에 row를 insert함으로써, 테이블별로 서로 다른 바이너리 로깅 포맷을 설정할 수 있습니다. 바이너리 로깅 포맷을 설정할 때는 앞의 표에 나온 내부 integer 값을 사용해야 합니다. 다음 두 문은 테이블 test.a에 대해 full row 로깅(값 3)을 설정하고, 테이블 test.b에 대해서는 update만 로깅(값 2)을 설정합니다:
1# Table test.a: Log full rows 2INSERT INTO mysql.ndb_replication VALUES("test", "a", 0, 3, 1, 0, NULL); 3 4# Table test.b: log updates only 5INSERT INTO mysql.ndb_replication VALUES("test", "b", 0, 2, 1, 0, NULL);
하나 이상의 테이블에 대한 로깅을 비활성화하려면, 다음과 같이 binlog_type에 대해 1을 사용합니다:
1# Disable binary logging for table test.t1 2INSERT INTO mysql.ndb_replication VALUES("test", "t1", 0, 1, 1, 0, NULL); 3 4# Disable binary logging for any table in 'test' whose name begins with 't' 5INSERT INTO mysql.ndb_replication VALUES("test", "t%", 0, 1, 1, 0, NULL);
특정 테이블에 대한 로깅을 비활성화하는 것은 sql_log_bin = 0을 설정하는 것과 동일하지만, 한 개 이상의 테이블에 개별적으로 적용된다는 점이 다릅니다.
어떤 테이블에 대해 SQL 노드가 바이너리 로깅을 수행하지 않으면, 해당 테이블에 대한 row 변경 이벤트는 이 노드에 전송되지 않습니다. 즉, 모든 변경 사항을 수신한 후 일부를 버리는 것이 아니라, 애초에 이러한 변경 사항에 subscribe하지 않는 것입니다.
로깅 비활성화는 다음에 나열된 이유들을 포함한 여러 이유로 유용할 수 있습니다:
네트워크를 통해 변경을 전송하지 않으면 일반적으로 대역폭, 버퍼링 및 CPU 리소스를 절약할 수 있습니다.
value가 크지 않은 빈번한 update가 발생하는 테이블에 대해 변경 사항을 로그하지 않는 것은, 클러스터가 완전히 장애가 날 경우 상대적으로 중요하지 않을 수 있는 transient 데이터(예: 세션 데이터)에 잘 맞습니다.
세션 변수(또는 sql_log_bin)와 애플리케이션 코드를 사용하면, 특정 SQL 문이나 특정 유형의 SQL 문을 로그하거나 로그하지 않도록 하는 것도 가능합니다. 예를 들어, 어떤 경우에는 하나 이상의 테이블에 대한 DDL 문을 기록하지 않는 것이 바람직할 수 있습니다.
복제 스트림을 두 개(또는 그 이상)의 바이너리 로그로 분리할 수 있습니다. 이는 성능상의 이유, 서로 다른 데이터베이스를 서로 다른 위치로 복제해야 하는 필요성, 서로 다른 데이터베이스에 대해 서로 다른 바이너리 로깅 타입을 사용해야 하는 경우 등 다양한 이유에서 사용될 수 있습니다.
Per-table binary log slicing.
binlog_row_slice_count 및 binlog_row_slice_id 컬럼에 적절한 값을 insert하여, 특정 테이블에 대한 로깅을 여러 MySQL 서버에 분산시킬 수 있습니다. binlog_row_slice_count는 바이너리 로그 slice 수이며, 이 그룹에 속하는 모든 MySQL 서버에서 동일해야 합니다. binlog_row_slice_id는 특정 서버에서 어떤 slice를 해당 서버의 바이너리 로그에 기록할지 결정합니다.
예를 들어, 다음 row들을 테이블에 insert하면, slice ID가 0인 mysqld는 테이블 t1에 대한 row 변경의 절반을 로그하고, slice ID가 1인 다른 mysqld는 나머지 절반을 로그하게 됩니다:
1mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t1", 1, 2, 2, 0, NULL); 2mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t1", 2, 2, 2, 1, NULL);
두 문 모두 binlog_row_slice_count 컬럼에 2를 insert합니다. 마찬가지로, 다음과 같이 ndb_replication 테이블에 네 개의 row를 insert하고, 각 row에서 binlog_row_slice_count 컬럼에 4를 사용하며 binlog_row_slice_id 컬럼에는 연속된 ID를 사용하면, t2에 대한 바이너리 로깅을 네 개의 slice로 나눌 수 있습니다:
1mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t2", 1, 2, 4, 0, NULL); 2mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t2", 2, 2, 4, 1, NULL); 3mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t2", 3, 2, 4, 2, NULL); 4mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t2", 4, 2, 4, 3, NULL);
또한 ndb_replication 테이블에 중복 row를 insert함으로써 slice별 redundant 로깅을 구성할 수도 있습니다. 예를 들어, 다음 INSERT 문은 각기 세 개의 서버로 구성된 두 개의 그룹을 생성하며, 각 그룹은 테이블 t3에 대한 바이너리 로깅을 세 개의 slice로 나눕니다:
1mysql> INSERT INTO mysql.ndb_replication 2 -> VALUES 3 -> ("test", "t3", 1, 2, 3, 0, NULL), 4 -> ("test", "t3", 2, 2, 3, 1, NULL), 5 -> ("test", "t3", 3, 2, 3, 2, NULL), 6 -> ("test", "t3", 4, 2, 3, 0, NULL), 7 -> ("test", "t3", 5, 2, 3, 1, NULL), 8 -> ("test", "t3", 6, 2, 3, 2, NULL);
또한, 특정 MySQL Cluster 내 모든 NDBCLUSTER 테이블에 대해 보다 일반적인 방식으로(한 번에) 이 작업을 수행하는 것도 가능합니다. 이를 위해서는 서버를 --ndb-log-row-slice-count 및 --ndb-log-row-slice-id 옵션과 함께 시작하면 됩니다. 자세한 내용은 각 옵션의 설명을 참조하십시오.
Matching with wildcards.
복제 구성에서 데이터베이스, 테이블, SQL 노드 각각의 조합마다 ndb_replication 테이블에 row를 insert해야 하는 부담을 줄이기 위해, NDB는 이 테이블의 db, table_name, server_id 컬럼에서 와일드카드 매칭을 지원합니다. db와 table_name에 사용되는 데이터베이스 및 테이블 이름에는 다음 와일드카드 중 하나 또는 둘 다를 포함할 수 있습니다:
_ (underscore 문자): 0개 이상의 문자를 매칭% (percent 기호): 단일 문자를 매칭(이는 MySQL의 LIKE 연산자가 지원하는 와일드카드와 동일합니다.)
server_id 컬럼은 _(모든 것과 일치)을 의미하는 와일드카드와 동등한 0을 지원합니다. 이는 앞서 제시된 예제에서 사용되었습니다.
ndb_replication 테이블의 특정 row는 데이터베이스 이름, 테이블 이름, 서버 ID 중 어느 것이든, 어떤 조합으로든 와일드카드를 사용하여 매칭할 수 있습니다. 테이블에 여러 개의 잠재적 match가 있는 경우, 다음 표에 따라 최선의 match가 선택됩니다. 여기서 _W_는 와일드카드 match, _E_는 exact match를 의미하며, Quality 컬럼의 값이 클수록 match 품질이 더 좋음을 의미합니다:
Table 25.44
Weights of different combinations of wildcard and
exact matches on columns in the mysql.ndb_replication
table
db | table_name | server_id | Quality |
|---|---|---|---|
| W | W | W | 1 |
| W | W | E | 2 |
| W | E | W | 3 |
| W | E | E | 4 |
| E | W | W | 5 |
| E | W | E | 6 |
| E | E | W | 7 |
| E | E | E | 8 |
따라서 데이터베이스 이름, 테이블 이름, 서버 ID 모두에 대한 exact match가 가장 좋은(가장 강한) match로 간주되며, 세 컬럼 모두에 대한 와일드카드 match가 가장 약한(가장 나쁜) match입니다. 어떤 rule을 적용할지 결정할 때는 match 강도만 고려되며, 테이블에서 row가 등장하는 순서는 전혀 영향을 미치지 않습니다.
Logging Full or Partial Rows.
mysqld에 대해 --ndb-log-updated-only 옵션을 어떻게 설정했는지에 따라, row 로깅에는 두 가지 기본 방법이 있습니다:
ON으로 설정)OFF로 설정했을 때의 기본 동작입니다.일반적으로는 업데이트된 컬럼만 로그하는 것으로 충분하며, 이 방식이 더 효율적입니다. 그러나 full row를 로그해야 할 필요가 있는 경우, --ndb-log-updated-only을 0 또는 OFF로 설정하여 이를 수행할 수 있습니다.
Logging Changed Data as Updates.
MySQL Server의 --ndb-log-update-as-write 옵션 설정은 로깅이 “before” image를 포함하여 수행될지 여부를 결정합니다.
update 및 delete 작업에 대한 conflict resolution은 MySQL Server의 update handler에서 수행되기 때문에, 복제 소스에서 수행되는 로깅을 제어하여 update가 write가 아닌 update로 처리되도록 해야 합니다. 즉, update가 기존 row를 대체하여 새로운 row를 쓰는 것이 아니라, 기존 row에 대한 변경으로 처리되도록 해야 합니다.
이 옵션은 기본적으로 켜져 있습니다. 즉, update는 write로 취급됩니다. 다시 말해, update는 바이너리 로그에 기본적으로 update_row 이벤트가 아니라 write_row 이벤트로 기록됩니다.
이 옵션을 비활성화하려면, 소스 mysqld를 --ndb-log-update-as-write=0 또는 --ndb-log-update-as-write=OFF와 함께 시작해야 합니다. 이는 NDB 테이블에서 다른 스토리지 엔진을 사용하는 테이블로 복제할 때 반드시 수행해야 합니다. 자세한 내용은 Replication from NDB to other storage engines 및 Replication from NDB to a nontransactional storage engine을 참조하십시오.
주의
NDB$MAX_INS() 또는 NDB$MAX_DEL_WIN_INS()를 사용한 insert conflict resolution에서는, SQL 노드(즉, mysqld 프로세스)가 idempotency와 최적의 크기를 위해 소스 클러스터에서의 row update를 --ndb-log-update-as-write 옵션을 활성화한 상태로 WRITE_ROW 이벤트로 기록할 수 있습니다. 이 알고리즘들은 둘 다 row의 존재 여부에 따라 WRITE_ROW 이벤트를 insert 또는 update로 매핑하며, 필요한 메타데이터(즉, timestamp 컬럼에 대한 “after” image)가 “WRITE_ROW” 이벤트에 포함되어 있기 때문에, 이러한 방식이 유효합니다.
25.7.3 Known Issues in NDB Cluster Replication
25.7.5 Preparing the NDB Cluster for Replication